"This post compares the performance of TensorRT-LLM and llama.cpp on consumer NVIDIA GPUs, highlighting the trade-offs among speed, resource usage, and convenience." # Description used for search engine.
Read more here: External Link
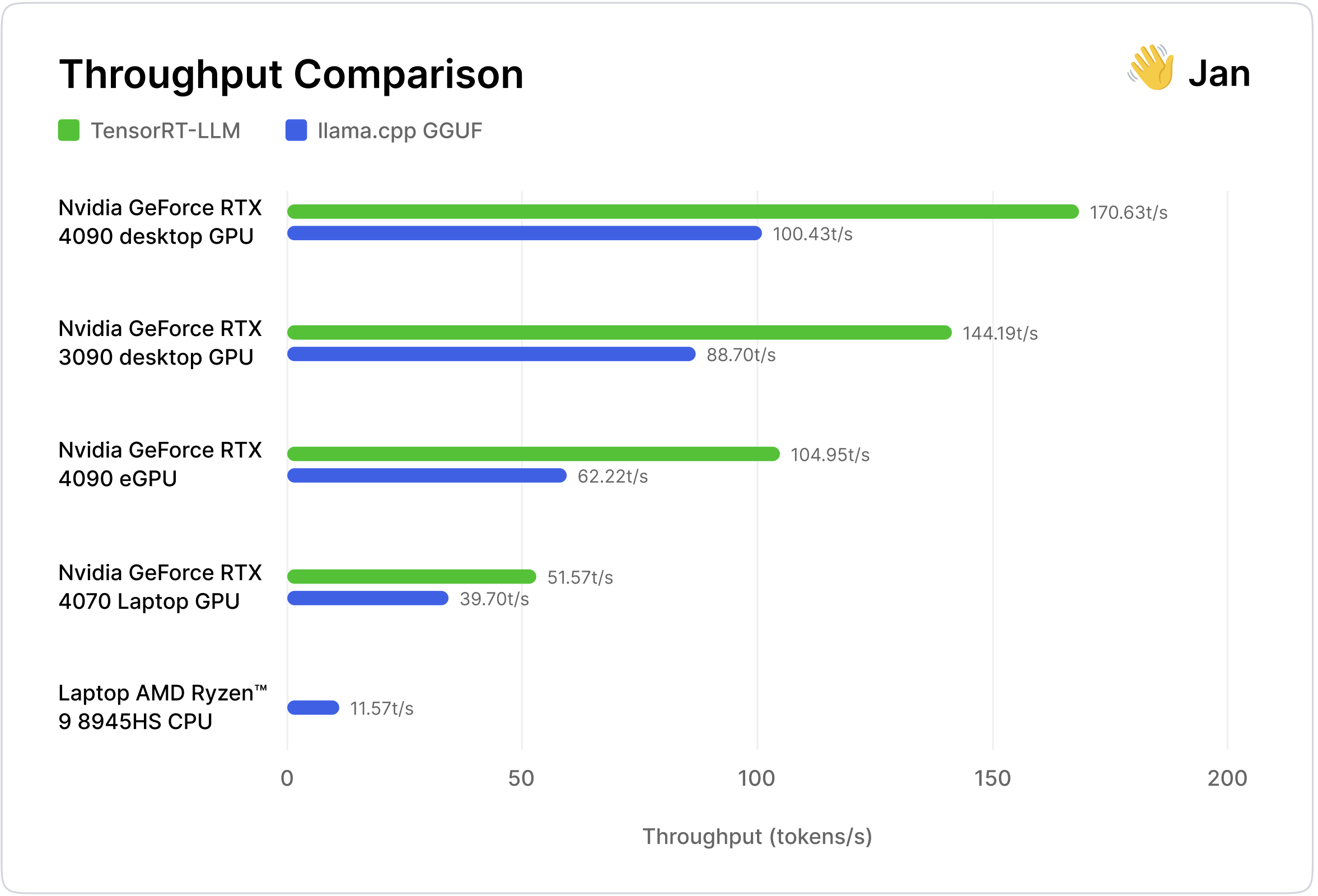
"This post compares the performance of TensorRT-LLM and llama.cpp on consumer NVIDIA GPUs, highlighting the trade-offs among speed, resource usage, and convenience." # Description used for search engine.
Read more here: External Link