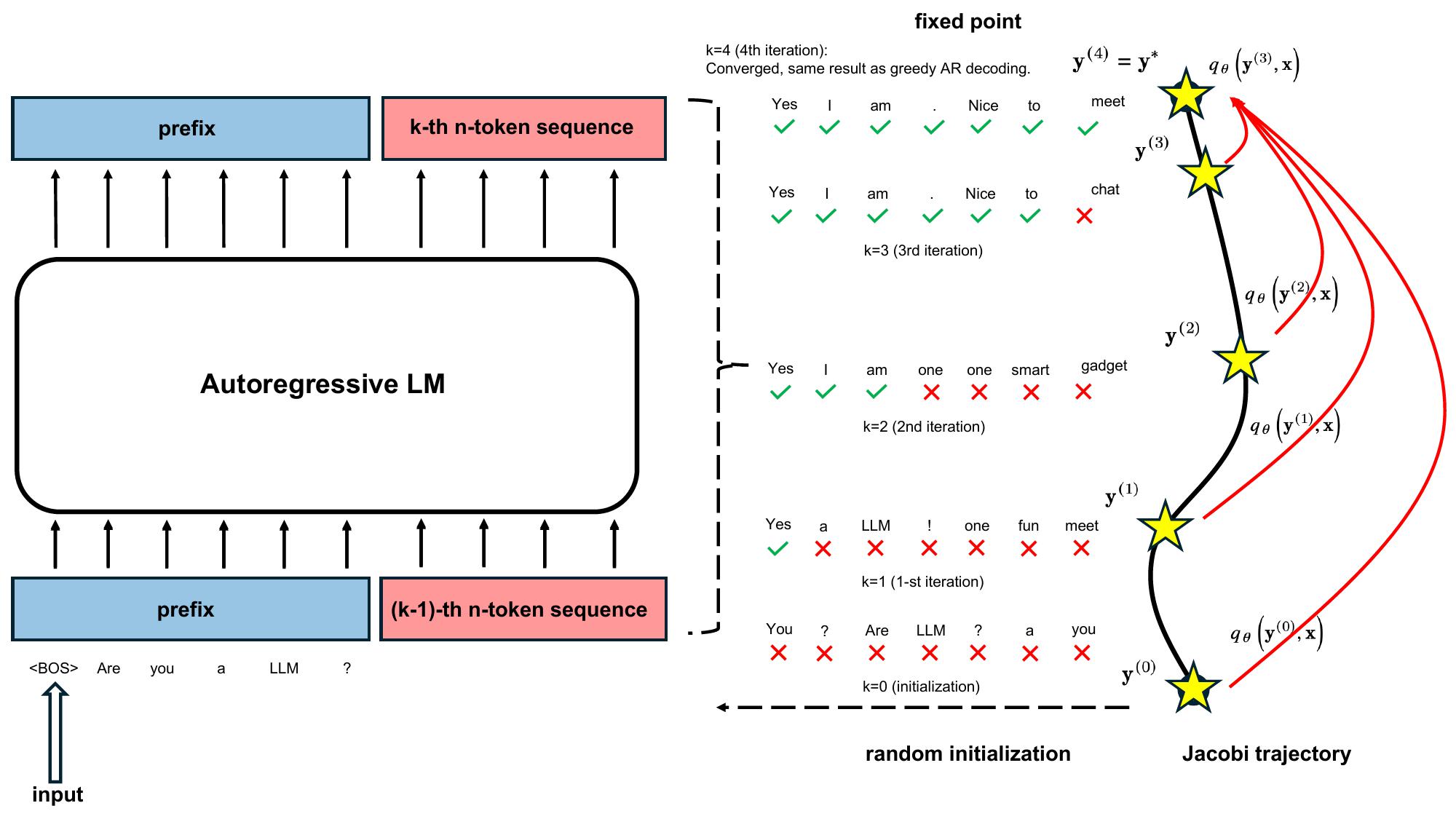
"TL;DR: LLMs have been traditionally regarded as sequential decoders, decoding one token after another. In this blog, we show pretrained LLMs can be easily taught to operate as efficient parallel decoders. We introduce Consistency Large Language Models (CLLMs), a new family of parallel decoders capable of reducing inference latency by efficiently decoding an $n$-token sequence per inference step. Our research shows this process – mimicking human cognitive process of forming complete sentences in mind before articulating word by word – can be effectively learned by simply finetuning pretrained LLMs." # Description used for search engine.
Read more here: External Link