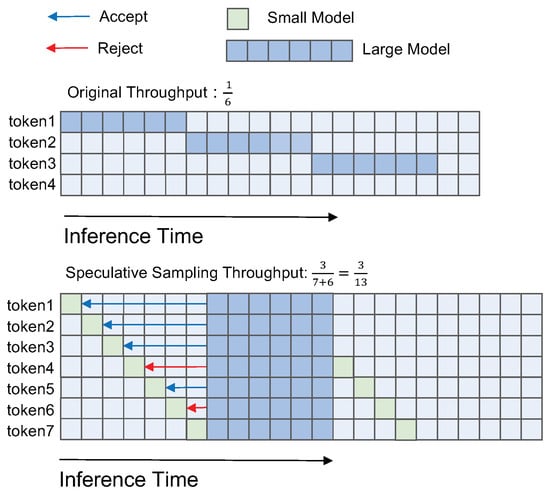
"As the size of deep learning models continues to expand, the elongation of inference time has gradually evolved into a significant challenge to efficiency and practicality for autoregressive models. This work introduces a hybrid model acceleration strategy based on branch prediction, which accelerates autoregressive model inference without requiring retraining and ensures output consistency with the original model. Specifically, the algorithm employs two models with different parameter sizes aimed at the same task. The smaller model generates a series of potential tokens that are then parallelly validated by the larger model to determine their acceptability. By orchestrating the workflow of the large and small models through a branch-prediction strategy, the algorithm conceals the validation time of the larger model when predictions are successful, thereby accelerating inference. We propose a binomial distribution-based prediction function that blends theoretical principles with empirical evidence, specifically designed for the nuanced requirements of accelerating inference within a hybrid model framework. The entire algorithm was designed and implemented on the llama model for text generation and translation tasks. The experimental results indicate significant improvements. The proposed algorithm achieves a 1.2× to 3.4× increase in inference speed compared to the original model, consistently outperforming the speculative sampling inference acceleration algorithm." # Description used for search engine.
Read more here: External Link