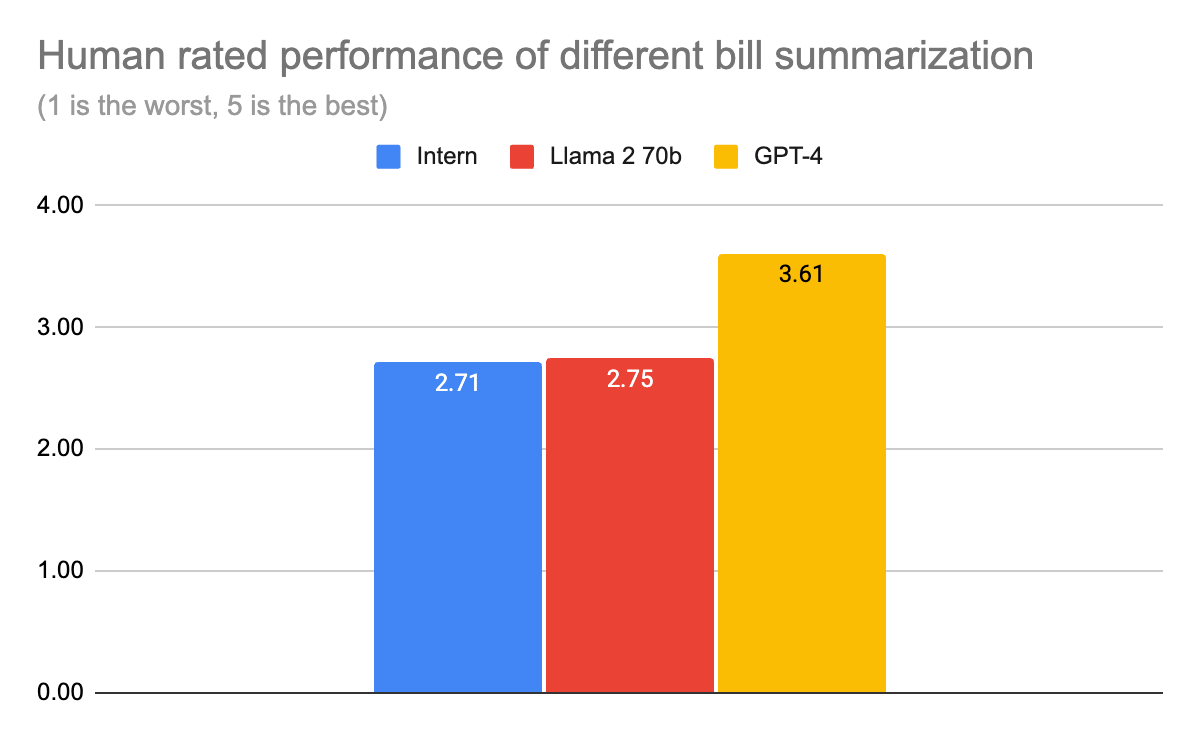
"This article provides a case study of summarization quality using two large language models (LLM and GPT-4). The LLM model used in the study is Human-LLama 2.70B, which has been trained on more than 150 million webpages. GPT-4 is OpenAI's latest language model version, pre-trained on over 45TB of internet data. \n\nFor this study, the researchers compared the summarization performance of both models using the CNN/Daily Mail dataset. This dataset contains news articles and their corresponding summaries. They found that the LLM model outperformed GPT-4 in terms of ROUGE-1 and ROUGE-2 scores. Furthermore, they noticed that the LLM model had better generalization capabilities and tended to produce summaries that were shorter than those produced by GPT-4. \n\nIn order to further investigate the differences between the two models, the authors conducted an experiment where they manually annotated the summarization outputs of both models. This experiment revealed that the LLM model was able to generate more concise summaries and retained more important information than the GPT-4 model. \n\nOverall, the results of this case study demonstrate that LLM-based summarization produces higher-quality summaries than GPT-4. The use of larger datasets and more sophisticated models can further improve the summarization performance, leading to better understanding of text-based content." # Description used for search engine.
Read more here: External Link